If you would like to read and process 1 Billion records from HBase, how long it would take? To simplify the scenario the following example reads all the messages from a HBase table and just count the number of rows instead of really processing all the messages.
It states how fast we can read the messages from HBase in a MapReduce job for processing. In a real scenario the processing time of the messages would be extra, but it provides a hint about the time required to read 1 Billion records from the HBase.
To run the above program:
hadoop jar <jar file name> HbaseRowCounter <table name>
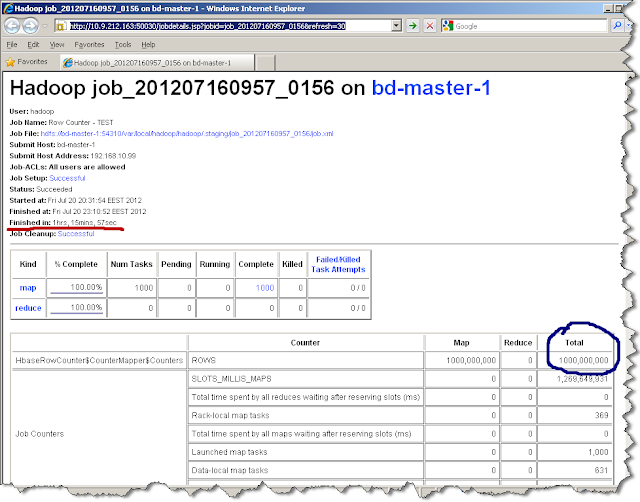
The following snapshot shows the hadoop job output and the processing time to read and count the 1 Billion records it takes about 1 hour 15 minutes.
The performance testing is done with 8 node cluster each of 4 quad core 32 GB RAM. Also the table have only 1 column family and single column with record size of each row is approx 150 bytes. The table is also pre-partitioned with 1000 regions.

It means to calculate the total sales from 1 Billion records; each having the instance of selling it would take minimum of 7-8 minutes..
It states how fast we can read the messages from HBase in a MapReduce job for processing. In a real scenario the processing time of the messages would be extra, but it provides a hint about the time required to read 1 Billion records from the HBase.
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.output.NullOutputFormat;
public class HbaseRowCounter {
public static class CounterMapper extends TableMapper<Text, Text> {
public static enum Counters {
ROWS
}
public void map(ImmutableBytesWritable row, Result value,
Context context) throws InterruptedException, IOException {
context.getCounter(Counters.ROWS).increment(1);
}
}
public static void main(String[] args) throws Exception {
if (args.length != 2) {
System.out.println("Usage: HbaseRowCounter <tablename>");
System.exit(0);
}
Configuration config = HBaseConfiguration.create();
Job job = new Job(config, "Row Counter - " + args[0]);
job.setJarByClass(HbaseRowCounter.class);
Scan scan = new Scan();
//scan.setCaching(1000);
TableMapReduceUtil.initTableMapperJob(args[0], // input table
scan, // Scan instance
CounterMapper.class, // mapper class
Text.class, // mapper output key
Text.class, // mapper output value
job);
job.setOutputFormatClass(NullOutputFormat.class);
job.setNumReduceTasks(0); // at least one, adjust as required
boolean b = job.waitForCompletion(true);
if (!b) {
throw new IOException("error with job!");
}
}
}
To run the above program:
hadoop jar <jar file name> HbaseRowCounter <table name>
The following snapshot shows the hadoop job output and the processing time to read and count the 1 Billion records it takes about 1 hour 15 minutes.
The performance testing is done with 8 node cluster each of 4 quad core 32 GB RAM. Also the table have only 1 column family and single column with record size of each row is approx 150 bytes. The table is also pre-partitioned with 1000 regions.

As it seems quite high, we started looking the ways to optimize it and found caching of the scan object can really improve the performance. The following HBase book contains the details. Please enable the commented blue line in the source code for scan caching. The scan caching avoids the rpc calls for each invocation from the map task to the region-server as described in the blog. After setting the scan caching we could read the 1 Billion records in just 7 minutes 44 seconds.

It means to calculate the total sales from 1 Billion records; each having the instance of selling it would take minimum of 7-8 minutes..
Note that the setCaching option can be set using the configuration property hbase.client.scanner.caching, without changing the code. Please see the following link for details.
Worthful Hadoop tutorial. Appreciate a lot for taking up the pain to write such a quality content on Hadoop course. Just now I watched this similar Hadoop tutorial and I think this will enhance the knowledge of other visitors for sure. Thanks anyway.https://www.youtube.com/watch?v=1OFFAr8zYEY
ReplyDelete